这一事件指的是发生在北京时间 2025年11月18日晚间(UTC时间11月18日中午) 的Cloudflare大规模服务中断。由于Cloudflare作为全球互联网基础设施的重要地位,这次宕机对全球大量网站和应用造成了显著影响。
以下是对该事件的详细回顾与总结:
1. 事件概览
- 发生时间:北京时间 2025年11月18日 19:20 左右(UTC 11:20)。
- 持续时间:主要故障持续了约 2-3小时,随后逐步恢复。
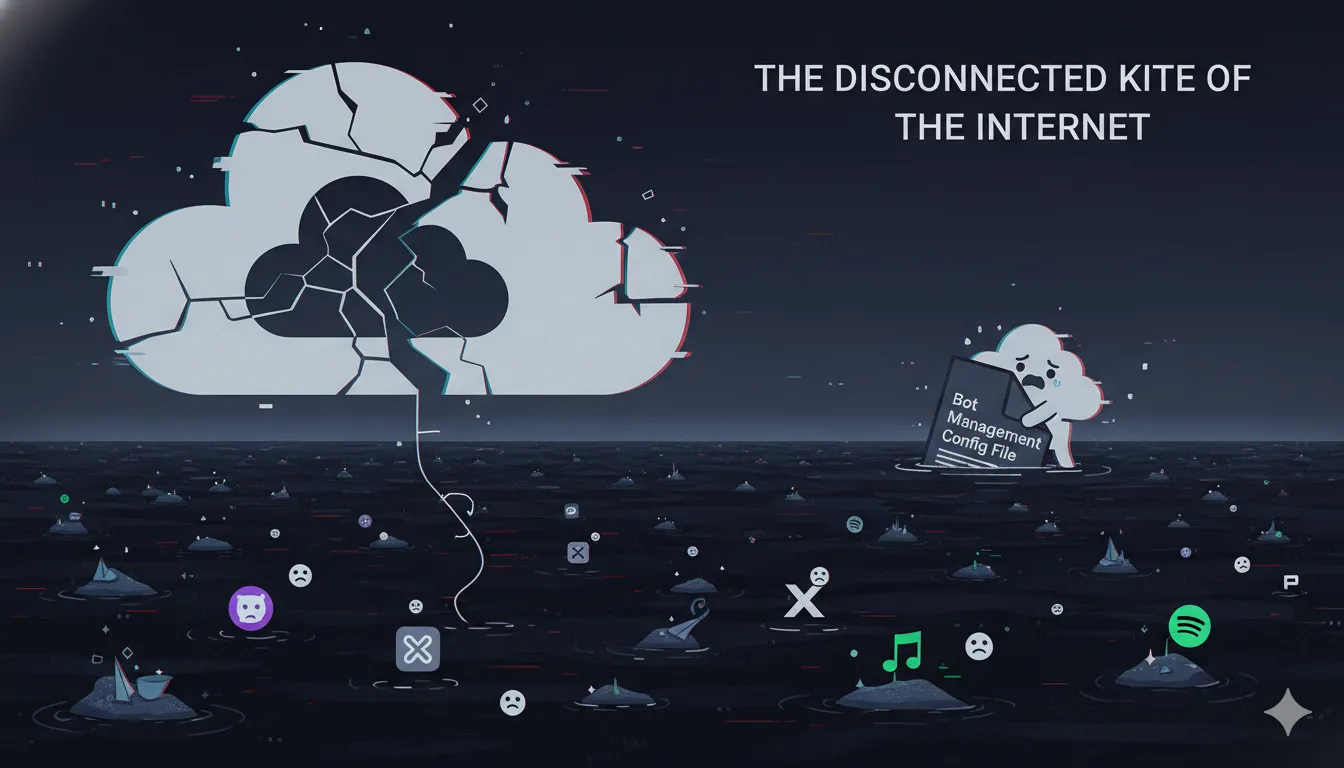
- 事件性质:由于Cloudflare是全球最大的内容分发网络(CDN)和安全服务提供商之一,其故障导致“半个互联网”瘫痪,用户普遍遭遇
500 Internal Server Error或无法连接的状况。
2. 影响范围
这次宕机具有全球性,波及了依赖Cloudflare基础设施的众多知名服务和平台,包括但不限于:
- AI与生产力工具:ChatGPT (OpenAI)、Claude (Anthropic)、Canva、Notion。
- 社交与媒体:X (原Twitter)、Discord、Spotify。
- 其他服务:部分加密货币交易所(如Coinbase)、电商平台(如Shopify)以及由Cloudflare托管的无数中小型网站。
- 典型症状:
- 用户访问网站时看到
Error 500错误代码。 - 出现特殊的错误提示:“Please unblock https://www.google.com/search?q=challenges.cloudflare.com to proceed”,这表明Cloudflare的安全验证机制本身出现了故障。
- 甚至连监测网站宕机的平台 DownDetector 和 Cloudflare 自身的系统状态页面(Status Page)在初期也一度无法访问。
- 用户访问网站时看到
3. 故障根因 (技术复盘)
根据Cloudflare的官方事后分析(Post-mortem),此次事故并非网络攻击(DDoS),而是由内部配置更新触发的软件缺陷(Bug)。
- 触发点:Cloudflare在此期间进行了一次常规的配置更新。
- 具体原因:
- 此次更新涉及**Bot Management(机器人管理)**模块的一个配置文件。
- 该生成的配置文件体积超出预期大小,触发了后端处理软件中的一个“潜伏Bug”(Latent Bug)。
- 这个Bug导致负责流量处理的软件系统崩溃(Crash)。具体来说,部署了新版代理引擎(FL2 proxy engine)的服务器开始拒绝服务,导致 HTTP 5xx 错误激增。
- 连锁反应:由于Bot Management是核心安全组件,其故障直接导致流量无法通过安全检查,进而阻断了对客户源站的访问。
4. 处置与恢复
- 发现问题:Cloudflare 工程师在UTC 11:20 左右监测到核心网络流量传输失败,最初曾误判为超大规模DDoS攻击,但很快排除了这一可能性。
- 缓解措施:工程师定位到问题源于Bot Management的配置文件后,实施了回滚(Rollback)操作,将配置文件恢复到之前的版本。
- 恢复上线:
- UTC 13:05 左右,回滚开始生效。
- UTC 14:42 左右(北京时间 22:42),官方宣布修复完成,绝大多数服务恢复正常。
- 随后一段时间内,团队继续修复仪表盘(Dashboard)访问和部分地区(如伦敦)的WARP服务连接问题。
5. 总结与启示
这次事件再次暴露了现代互联网**“中心化”脆弱性**的问题。
- 单点故障风险:Cloudflare 承载了全球约20%的网站流量,一旦其核心组件(如配置管理或安全网关)出现问题,会导致大面积的“数字交通瘫痪”。
- DevOps 教训:即便是顶级技术公司,在配置文件的边界检查(如文件大小限制)和异常处理(Error Handling)上仍可能存在疏漏。这次“潜伏Bug”是在特定的大文件输入下才被触发,提示了在生产环境变更中进行更严格的压力测试和金丝雀发布(Canary Release)的重要性。